Relevance of Historised and Scalable Data Architectures for ML and AI
In a world of ever-growing data sources and collection possibilities it is of importance to utilise data as efficiently as possible. Regardless of the final product being data analytics applications, artificial intelligence, or machine learning applications, to utilise the full capabilities of our customer’s data we need to build robust, highly scalable and historised data architectures to provide the best data insight but also leverage the flexibility for further growth and improvement.
The best data foundation is one that can be adjusted and expanded but has a long-term memory of its own.
Here I want to introduce a few key concepts that are crucial for a robust data architecture on which we can build ML applications or set the foundation for artificial intelligence.

The role of a Data Vault in Modern Data Lakehouse Architectures
Data Vault is a methodology designed to track every data change occurring in your data, serving as the core long term memory in your data architecture. The design principles make it a versatile tool to scale and adjust the data model according to changing needs. It deconstructs complex relationships between data and opens the possibility to quickly adjust the model. It can be described as a hybrid approach between 3NF and star schema modelling.[1]
A Data Vault mainly consists of a multitude of three different core data objects:
- Hub – A hub stores unique business keys.
- Link – Connect different hubs with each other.
- Satellite – Storage of descriptive and historical data.
Even though the Data Vault concept already exists for over 2 decades, it fits well within the modern concepts of Cloud based Data Architectures and Data Lakehouses.
Instead of storing data in a traditional Data Warehouse, the Data Vault objects reside within one layer of a cloud native architectural concept, feeding from a data lake and serving sematic layers for business purposes.
The implementation within a cloud-based architecture makes it possible to process a high volume of data and offers near limitless storage.
Usually, the Data Vault is implemented as a raw vault and a business vault. The former captures the data without any business logic, and the latter prepares the data according to business needs and KPIs.
Serving Business Data – Data Marts
Using a business vault as an entry point to business logic, a Data Mart layer serves the data historically correct, usually modelled in a Star Schema. A Data Mart utilises two different data objects [2]:
- Facts – storage of operational data, such a, i.e., sale transactions.
- Dimensions – normalized and descriptive data – historized.
Reporting applications for business units usually are built on top of the Data Mart and allow the business units to report on the data structures specifically built for the purpose of their unit.
Historisation
The crucial point to keep a long-term memory and maintenance of historical accuracy of data is to properly implement historisation concepts throughout the different layers in your data architecture.
The main point to emphasize for proper historical data is to track everything. Data sources that create timestamps when generating the data are the best thing that can happen to you and your data architecture. If the sources do not provide a timestamp, create them as soon as the data is pulled from the source or pushed into your platform. Implement metadata and track every step through every layer of the architecture.
The implementation of robust change data capture (CDC) can help in reducing data redundancy and only tracking real data changes into the layers which store tabular data.
Not knowing when data has been created is one of the most common problems to face when building data platforms.
One robust historisation concept of data within the modelling frameworks mentioned earlier is keeping track according to SCD2 type historisation [3] (slowly changing dimensions) when writing into the Data Vault objects and into the Data Mart.
SCD2 type historisation keeps track of a unique business key over the course of time and applies a validity timespan to a row of data. By keeping track of every data change for the key as seen in the example below for a product table (key column “id”), we provide a full history. Staging a new entry for an id which is already in the target table starts the following process in the historisation: We need to compare the existing content of the data for the id regarding changes of the data. If there is a change in the data, the row in the target table will be invalidated and the time interval will be closed with the timestamp of the incoming row of new data. The new row of data will be inserted with an infinite validity time until the row of data is either updated or deleted in the future. In case of a deletion, the validity of the row of data is set to the timestamp when the deletion occurs, and the row will be marked as “is_current” == false. Tracking of the merge operations (insert/update/delete) on the target table on every row can be useful as well.
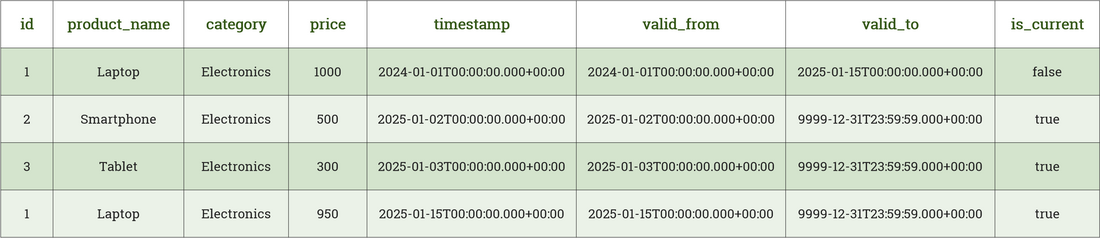
SCD2 historized tables serve as the starting point for further analysis and point in time views on different tables.
Populating Point in Time Tables using a Unified Timeline Approach
As the needs of ML applications and Large Language Models differ from the usual business reporting tables one encounters, it is necessary to properly serve data for these applications.
Imagine a flat table used as training data for a machine learning algorithm. The data science team should be enabled to pull data in a historically accurate manner from the core structures implemented in the architecture. Let it be the raw vault or the business vault or from the Data Mart. The different objects in the vault might be structured in a way that do not reflect the features which are important for the algorithm, introducing the need to create a dataset with different logic than implemented by business rules and aggregations. The ability to create training data that can be dated back and forth in time is invaluable for the extraction of trends and making predictions and retraining models with varying features and assign training data with model versions.
To pull together data for a training set from multiple historised tables using SCD2, one needs to join these tables while preserving the full historical context, effectively creating Point-In-Time tables. When trying to join on a unified timeline it is important that the tables to join have the same keys.
Below, we provide a short SQL Code example using the product table from above, combined with a warehouse table.

The unique id is the same for the storage facility table as well as the product table. The resulting Point-In-Time table needs to reflect the historical information of the products and where they are physically located.
%sql
with
unified_timeline as (
select id, timestamp, valid_from from products
union
select id, timestamp, valid_from from warehouse
),
unified_timeline_recalculate_valid_to as (
select
id,
timestamp,
valid_from,
coalesce(
lead(valid_from) over(partition by id order by valid_from),
'9999-12-31 23:59:59'::timestamp
) as valid_to,
valid_to = '9999-12-31 23:59:59'::timestamp AS is_current
from unified_timeline
),
joined as (
select
timeline.id,
products.product_name,
products.price,
products.category,
warehouse.location,
warehouse.facility,
timeline.timestamp,
timeline.valid_from as valid_from,
timeline.valid_to as valid_to,
timeline.is_current
from unified_timeline_recalculate_valid_to as timeline
left join products
on timeline.id = products.id
and products.valid_from <= timeline.valid_from
and products.valid_to >= timeline.valid_to
left join warehouse
on timeline.id = warehouse.id
and warehouse.valid_from <= timeline.valid_from
and warehouse.valid_to >= timeline.valid_to
)
select * from joined order by id, timestamp ascCreating a unified timeline means generating a single timeline that covers all possible periods in time where a key exists. The validity intervals are recalculated and represent every time slice for the chosen key [4]. By joining the historised tables to the timeline using the key, the data is properly connected in an historically accurate manner. In the finished unified timeline table, the history of the combined products and warehouse tables is visible. Every change in either table is represented by a separate entry.

The result of such a historised table can then either be provided directly to train ML models or modified to be written into vector databases from which large language models pull their information.
Transformer-based models, need high quality, contextually accurate data to be trained properly. Data which is pulled from Point-In-Time tables, enables the models to accurately learn the temporal contexts and answer correctly, improving the quality of your application.
Regardless of the final application, a solid historisation increases the value of data and a flexible, scalable, and robust data architecture is the key factor and the foundation to ensure high quality data, better data products and more value generated from the data assets.
Sources
[1]https://tdan.com/data-vault-series-1-data-vault-overview/5054
[2]https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/fact-table-structure/
[3]https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/type-2/
[4]https://infinitelambda.com/multitable-scd2-joins/

Alexandra Terwey is a Senior Consultant at Woodmark Consulting AG. Having a background in experimental physics, she now specializes in Data Engineering and is working on flexible Data Architectures from source to application.